이번에는 Rust로 SQLite의 한국어 형태소 분석기 확장을 만들어 봤다. 또 바이브 코딩 이야기인가? 그렇다. 분야는 다르지만 결국 바이브 코딩 이야기이다. 온라인에 넘쳐나는 다른 바이브 코딩 간증글과 다르다고 자신 있게 말하기는 어렵다. 그러니 뒤로 가기를 누르거나, 글 말미에 있는 프로젝트 링크로 바로 건너뛰어도 좋다.
참고: 이 글은 한 땀 한 땀 수제로 작성했다(AI의 조언은 받았다).
시작
원래도 한국어라는 언어를 다루는 일에 관심이 많았다. 관심에 비해 대단한 활동을 하지는 않았지만 어쨌든 관심은 꾸준히 있었다. 최근 어떤 사이드 프로젝트를 계획하면서 자연어 처리에 예전보다는 많은 관심을 기울이기 시작했다. 그렇다고 아무 경험도 없던 사람이 모든 걸 처음부터 만들 만큼 호락호락한 분야는 아니었기 때문에 내가 올라탈 거인의 어깨를 찾기 시작했다.
많은 형태소 분석 라이브러리를 보았고, 잠정적으로 내 용도에는 mecab-ko와 kiwi가 맞을 것 같아서 슬쩍 살펴보는 중이었다. 그러다가 어제 가루라는 형태소 분석기 프로젝트를 보았다. 모델과 엔진을 다 합쳐 2MB 남짓한 말도 안되게 가벼운 용량과 단순한 사용법이 마음에 들었다. 그래서 내가 필요했던 기능 중 하나인 SQLite의 한국어 형태소 분석기를 Garu 기반으로 만들어 보기로 했다.
경량 엔진인 만큼 정확도는 다소 떨어질지 모르나 풀텍스트 검색의 전처리 용도로는 충분할 것으로 보였다.
Phase 1 - 구현
퇴근하자마자 사이드 프로젝트 용도로 주로 사용하는 도구인 opencode를 열고 명세를 적어 나갔다. 사실 ‘SQLite FTS의 확장 기능’이라는 말만으로도 명세는 거의 완성된 것이나 다름없었다. ‘Garu를 기반으로 작성할 것’이라는 점만 잘 정해주면 되었다. 물론 Garu가 내 용도에 적합한지 다시 확인하는 과정도 잊지 않았다. 그 후 Garu 프로젝트의 코드를 분석하고 SQLite의 FTS5 확장 기능에 관해서도 찾아보라고 한 다음 충분한 계획을 세우고 구현하도록 했다.
시작한 지 한 시간 만에 빌드가 성공했다. 정확히 말하면 빌드만 성공했다.
미리 고백하자면 나는 Rust라는 언어를 깊이 알지는 못한다. 대략적인 지식만 있을 뿐, 애플리케이션이든 라이브러리든 바닥부터 작성해서 완성해 본 경험이 없다. 그러니 최초 작업까지는 그저 해달라는 대로 클릭만 해줄 뿐이었다. 한 번에 제대로 동작하지 않는 게 당연했다. 다행히 나는 바이브 코딩에 마법 같은 환상을 가질 세대는 아니었기 때문에 실망하지 않았다. 오히려 안심했다. 자, 이제 이것만 고치면 되겠구나.
SQLite 확장의 엔트리포인트 명명 규칙이나 FTS5 API를 가져오는 방식 등과 같은 몇 가지 문제는 에이전트가 자체적으로 진단해서 수정했다. 하지만 이런 문제를 해결하고 성공적으로 빌드가 되었음에도 SQLite 확장 기능이 로드되지 않는 문제가 있었다. 원인은 나였다.
사실 나는 이 확장 기능을 Bun의 SQLite 기능에 추가해서 사용하고 싶었다. 그래서 엔드투엔드 테스트는 Bun 환경에서 진행하도록 했다. Bun에도 SQLite3의 확장 기능을 읽어 들이는 loadExtension API가 존재한다. 그런데 동작하지 않았다.
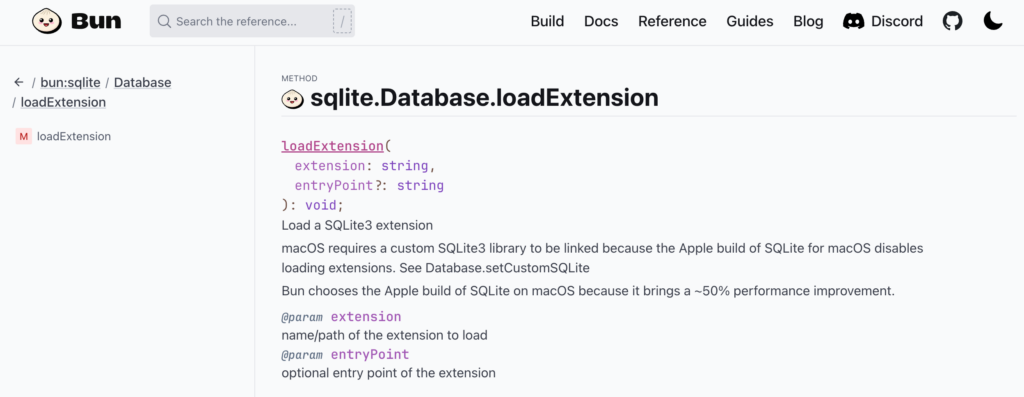
AI가 이것까지는 알려주지 않았다. 그냥 조용히 Bun이 안되는 것 같으니 better-sqlite3를 설치하겠다고 조를 뿐이었다. 그리고 better-sqlite3를 설치하면 말 그대로 수백 개의 패키지가 덩달아 설치된다. 빌드 과정에서 가볍게 테스트하려고 했는데 의도에 비해 너무 과했다.
왜 Bun에 내장된 SQLite를 사용할 수 없었을까? 공식 문서를 확인해 보니 MacOS 환경에서 Bun은 Mac에 기본 설치된 SQLite3 라이브러리를 로드하는데, 문제는 이 기본 라이브러리는 확장 기능을 허용하지 않는 플래그와 함께 빌드되었다는 것이다. 따라서 Mac 환경의 Bun에서 확장 기능을 사용하려면 brew 등으로 sqlite 패키지를 설치한 다음 데이터베이스 테이블을 만들기 전에 다른 SQLite 라이브러리를 로드해야 한다. 이를 위해 SQLite 라이브러리의 경로를 설정해 줘야 한다.

라이브러리의 절대 경로를 테스트에 하드 코딩해 두면 나중에 라이브러리 버전이 변경될 때마다 수작업으로 경로를 변경해야 한다. 그렇다고 경로를 자동으로 찾는 스크립트를 만들자니 배보다 배꼽이 크게 생겼다. 참고로 우리 라이브러리 코드는 주석을 다 합쳐도 400줄이 안 된다. 그래서 테스트 코드의 단순화를 위해 Bun은 제거하고 rusqlite을 기반으로 테스트를 작성했다. 이제 테스트-구현의 사이클을 문제없이 반복할 수 있게 됐다.
Phase 2 - 개선
그제야 테스트 코드를 살펴봤다. 그런데 작성된 테스트 케이스에는 어간이 같고 어미만 변화하는 사례를 반영하고 있지 않았다. 테스트 코드에 "달렸다", "달리는", "달리다"와 같이 어미가 변하는 케이스를 추가했다(정확히는 추가하라고 시켰다). 그리고 테스트가 실패했다.
원인은 두 가지 특성으로 인해 발생했다.
- Garu에서 반환한 모든 토큰을 그대로 반영했다.
- FTS5의 MATCH 연산은 AND가 기본 동작이다.
예를 들어 "달린다"라는 말을 토큰화하면 "달리" + "ㄴ다"가 된다. 이걸 그대로 저장한다고 가정해 보자. 그리고 내가 "달리다"를 검색하면 "달리" + "다"로 분해되어 "달리" AND "다"를 찾게 된다. 따라서 "달린다"는 검색되지 않는다. 명백하게 내 의도와는 다른 동작이었다. 이를 알기 쉽게 그림으로 표현하면 다음과 같다.
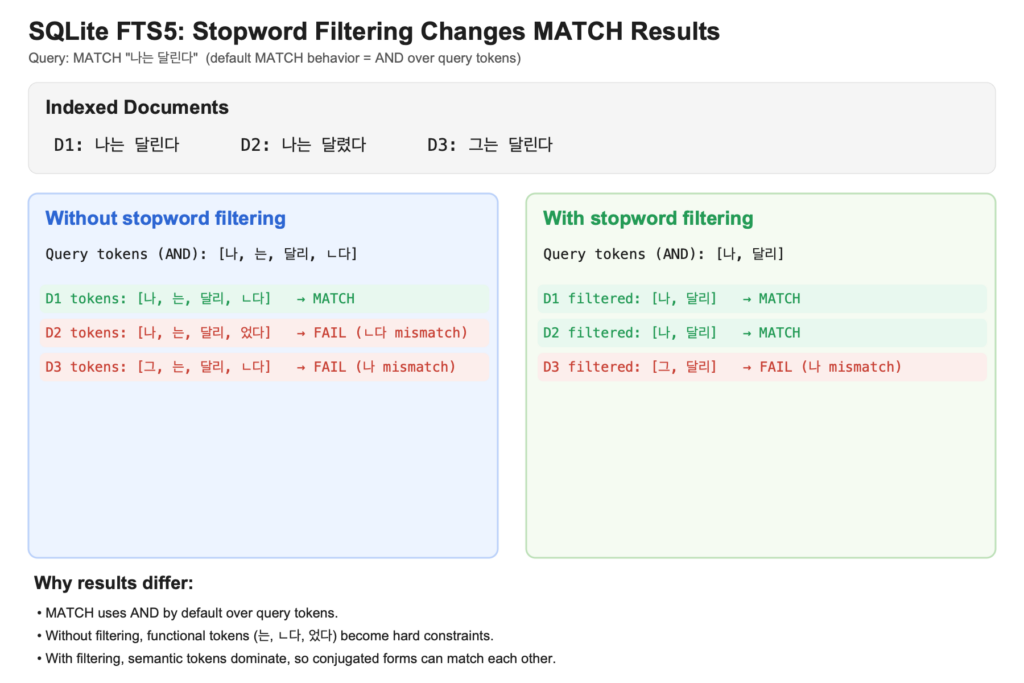
문제는 이해했다. 그런데, 이건 한국어의 특성 아닌가? 그렇다면 다른 검색 엔진의 형태소 분석기에서도 발생했을 문제였다. 그래서 가장 유명한 검색 엔진용 형태소 분석기인 Nori의 사례를 확인해 봤고(정확히는 확인해 보라고 시켰다), 불용어(stopword) 처리를 한다는 사실을 알게 됐다. 예전에 추천 시스템 관련해서 봤던 용어인데, 이럴 때도 사용된다는 사실을 배웠다. Nori를 참고해 불용어 처리를 했더니 드디어 의도대로 어간이 같은 텍스트가 검색되었다. 만세!
Phase 3 - 리뷰
공개하기 전에 모델을 바꿔 코드 리뷰를 시켰더니, 몇 가지 문제가 드러났다.
- 영어, 한자와 같은 외국어 그리고 숫자가 사라지는 문제가 있었다. 원인은 Nori의 불용어 태그를 가지고 오면서 제멋대로 확장한 기준을 적용해 버린 것이었다. (대체 왜?) 어쨌든 외국어와 숫자 토큰을 불용어에 포함하지 않도록 했다.
- 테스트를 살펴보니 검색어로 "달리"("달리다"의 어간)를 사용하고 있었다. 모르긴 몰라도 굳이 어간만 넣어서 검색하는 사람은 없을 것이다. 실제 사례에 가깝게 "달리다"의 여러 변형을 검색하며 테스트하도록 했다.
- 그리고 아주 작은 리팩토링도 진행했다. 코드가 워낙 짧아서 변경할 부분이 거의 없었다.
결론
코드를 어느 정도 완성하고 문서까지 작성하니, 여기까지 걸린 시간이 대략 3시간쯤이었다. 예전에 처음 바이브 코딩을 했을 때는 더 간단하고 익숙한 분야의 라이브러리를 만드는 데도 4시간이 걸렸는데, 이번에는 나에게 오히려 익숙하지 않은 분야를 더 짧은 시간에 끝냈다(당연히 1:1 비교가 어렵다는 건 안다).
내가 한 일이라고는 재벌 2세에 빙의해서 "그게 최선입니까?"라고 계속 닦달하는 것뿐이었다. 하지만 어디서 시작할지, 무엇을 확인할지, 어느 수준까지 완성도를 추구할지 정하는 것은 여전히 내 몫이었다.
이렇게 만든 sqlite-garu 프로젝트는 아래 저장소에서 볼 수 있다. 테스트가 더 필요하겠지만, 그전에라도 사용해 보고 의견을 주시면 감사한 마음으로 반영하겠다.